gitee仓库:sky-take-out: 黑马苍穹外卖
1.产品原型
1). 管理端
餐饮企业内部员工使用。 主要功能有:
2). 用户端
移动端应用主要提供给消费者使用。主要功能有:
2.技术选型
1). 用户层
在构建系统管理后台的前端页面,将用到Html5、Vue.js、ElementUI、apache echarts(展示图表)等技术。构建移动端应用时,会使用到微信小程序。
2). 网关层
Nginx是一个服务器,主要用来作为Http服务器,部署静态资源,访问性能高。在Nginx中还有两个比较重要的作用: 反向代理和负载均衡, 在进行项目部署时,要实现Tomcat的负载均衡,就可以通过Nginx来实现。
3). 应用层
SpringBoot: 快速构建Spring项目, 采用 "约定优于配置" 的思想, 简化Spring项目的配置开发(起步依赖、自动配置)。
SpringMVC:SpringMVC是spring framework的一个模块,即spring项目的web模块,如接收请求、响应数据、拦截器、全局异常处理。
Spring Task: 由Spring提供的定时任务框架。
httpclient: 主要实现了对http请求的发送。
Spring Cache: 由Spring提供的数据缓存框架
JWT: 用于对应用程序上的用户进行身份验证的标记。
阿里云OSS: 对象存储服务,在项目中主要存储文件,如图片等。
Swagger: 可以自动的帮助开发人员生成接口文档,并对接口进行测试。
POI: 封装了对Excel表格的常用操作。
WebSocket: 一种通信网络协议,使客户端和服务器之间的数据交换更加简单,用于项目的来单、催单功能实现。
4). 数据层
MySQL: 关系型数据库, 本项目的核心业务数据都会采用MySQL进行存储。
Redis: 基于key-value格式存储的内存数据库, 访问速度快, 经常使用它做缓存。
Mybatis: 本项目持久层将会使用Mybatis开发。
pagehelper: 分页插件。
spring data redis: 简化java代码操作Redis的API。
5). 工具
git: 版本控制工具, 在团队协作中, 使用该工具对项目中的代码进行管理。
maven: 项目构建工具,还可以使项目进行分模块开发。
junit:单元测试工具,开发人员功能实现完毕后,需要通过junit对功能进行单元测试。
postman: 接口测工具,模拟用户发起的各类HTTP请求,获取对应的响应结果。
3.项目结构
sky-common: 模块中存放的是一些公共类,可以供其他模块使用
sky-common模块的每个包的作用:
sky-pojo: 模块中存放的是一些 entity、DTO、VO
分析sky-pojo模块的每个包的作用:
sky-server: 模块中存放的是 配置文件、配置类、拦截器、controller、service、mapper、启动类等
sky-server模块的每个包的作用:
4. 数据库
表的说明:
5.前后端分离开发流程
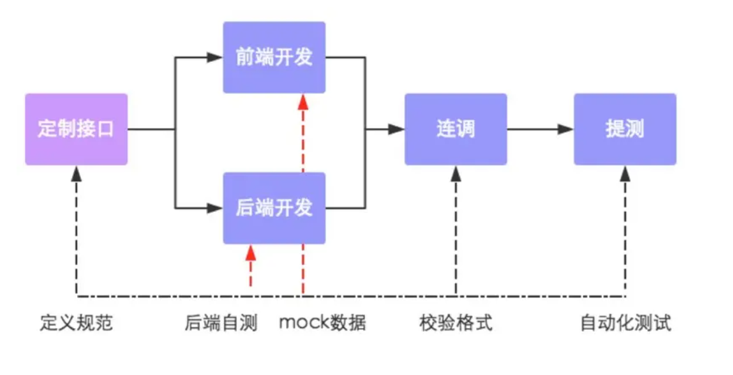
第一步:定义接口,确定接口的路径、请求方式、传入参数、返回参数。
第二步:前端开发人员和后端开发人员并行开发,同时,也可自测。
第三步:前后端人员进行连调测试。
第四步:提交给测试人员进行最终测试。
可以使用YAip管理接口YApi Pro-高效、易用、功能强大的可视化接口管理平台
导入json格式即可
(个人更推荐使用Apifox,相当于Yapi,postman,Swagger的集合)
6.Swagger
1.介绍
Swagger 是一个规范和完整的框架,用于生成、描述、调用和可视化 RESTful 风格的 Web 服务(https://swagger.io/)。 它的主要作用是:
使得前后端分离开发更加方便,有利于团队协作
接口的文档在线自动生成,降低后端开发人员编写接口文档的负担
功能测试
Spring已经将Swagger纳入自身的标准,建立了Spring-swagger项目,现在叫Springfox。通过在项目中引入Springfox ,即可非常简单快捷的使用Swagger。
knife4j是为Java MVC框架集成Swagger生成Api文档的增强解决方案,前身是swagger-bootstrap-ui,取名kni4j是希望它能像一把匕首一样小巧,轻量,并且功能强悍!
目前,一般都使用knife4j框架。
2.使用步骤
导入 knife4j 的maven坐标
在pom.xml中添加依赖
<dependency> <groupId>com.github.xiaoymin</groupId> <artifactId>knife4j-spring-boot-starter</artifactId> </dependency>在配置类中加入 knife4j 相关配置
WebMvcConfiguration.java
/** * 通过knife4j生成接口文档 * @return */ @Bean public Docket docket() { ApiInfo apiInfo = new ApiInfoBuilder() .title("苍穹外卖项目接口文档") .version("2.0") .description("苍穹外卖项目接口文档") .build(); Docket docket = new Docket(DocumentationType.SWAGGER_2) .apiInfo(apiInfo) .select() .apis(RequestHandlerSelectors.basePackage("com.sky.controller")) .paths(PathSelectors.any()) .build(); return docket; }设置静态资源映射,否则接口文档页面无法访问
WebMvcConfiguration.java
/** * 设置静态资源映射 * @param registry */ protected void addResourceHandlers(ResourceHandlerRegistry registry) { registry.addResourceHandler("/doc.html").addResourceLocations("classpath:/META-INF/resources/"); registry.addResourceHandler("/webjars/**").addResourceLocations("classpath:/META-INF/resources/webjars/"); }访问测试
接口文档访问路径为 http://ip:port/doc.html ---> http://localhost:8080/doc.html
思考:通过 Swagger 就可以生成接口文档,那么我们就不需要 Yapi 了?
1、Yapi 是设计阶段使用的工具,管理和维护接口
2、Swagger 在开发阶段使用的框架,帮助后端开发人员做后端的接口测试
7.常用注解
通过注解可以控制生成的接口文档,使接口文档拥有更好的可读性,常用注解如下:
8.个人见解
java序列化和反序列化
序列化:将对象转换成字节序列的过程,可以将对象持久化到本地磁盘或通过网络传输到远程机器。
反序列化:将字节序列转换回对象的过程
在网络传输中,数据需要以字节流的形式进行传输。字节流是指以字节为单位进行读取和写入的数据流。
而字节序列是指一系列字节的排列顺序。在对象序列化过程中,将对象转换为一连串的字节序列,这些字节按照特定的顺序组织起来,表示对象的各个属性和状态。因此,字节序列可以看作是对象序列化后得到的字节流。
序列化和反序列化的应用场景(本地JVM中运行java实例不需要序列化):
网络通信:在网络通信中,可以将对象进行序列化后通过网络传输到远端机器,这样可以实现远程过程调用(RPC)、分布式系统的协作等功能。如前端和后端之间需要进行交互和数据传输,这就需要通过网络实现通信。
数据持久化:通过序列化,可以将对象保存到磁盘或者数据库中,以便之后读取和恢复对象的状态。这在需要长期存储和恢复对象的情况下非常有用,例如将对象保存到文件系统、缓存、关系型数据库或NoSQL数据库中。
缓存机制:序列化和反序列化也广泛应用于缓存中,对于频繁访问的数据,可以将其序列化后存储到缓存中,减少数据库的访问次数,提高系统性能。
分布式计算:在分布式计算中,可以通过序列化和反序列化实现数据的传递和共享。例如,通过序列化和反序列化可以将任务对象发送给不同的计算节点,并在节点上执行任务。
消息队列:消息队列中的消息通常需要进行序列化和反序列化处理。生产者将消息对象序列化后发送到消息队列,消费者从队列中接收消息并进行反序列化,以获取消息内容。如RabbitMQ 进行消息传递时,序列化和反序列化是非常重要的步骤。
进程间通信:在进程间通信(IPC)中,通过序列化和反序列化可以在不同的进程之间传递数据。例如,通过管道、套接字等方式进行进程间通信时,可以将对象序列化后发送给接收方进程进行反序列化处理。Java 中对象都是存储在内存中,准确的说是 JVM 的堆或栈内存中。可以在各个线程之间进行对象传输,但是 无法 在 进程 之间进行传输。 如果需要在 网络传输中传输对象 也是 没有办法 的,而且内存中的对象也 没有办法 直接 保存成文件。
实现序列化和反序列化实现Serializable接口原因及注意事项:
如果要将一个 Java 对象序列化为字节流,那么该对象必须实现Serializable接口。该接口中没有任何方法,只是作为一个标记接口,告诉 JVM,该类可以被序列化,并且需要把哪些属性序列化到字节流中。
而实现Serializable接口还需要注意下面2个点:
1.序列化版本号:即指定serialVersionUID的值。如果不显示指定serialVersionUID, JVM在序列化时会根据类的细节自动生成一个serialVersionUID值, 然后与属性一起序列化。(具体来说,JVM 会基于类的名称、访问修饰符、非瞬态和非静态字段以及方法和构造函数等细节计算出一个长整型数值,并将其作为默认的 serialVersionUID 值。) 再进行持久化或网络传输. 在反序列化时, JVM会再根据细节自动生成一个新版serialVersionUID, 然后将这个新版serialVersionUID与序列化时生成的旧版serialVersionUID进行比较, 相同则反序列化成功, 否则报InvalidClassException 异常。
但是这种自动生成的serialVersionUID 可能因为修改类定义而发生改变,从而导致无法正确地进行对象的反序列化。因此,虽然 serialVersionUID 的确可以被自动生成,但是我们无法避免版本不会迭代,类不再修改。因此我们可以指定一个serialVersionUID,防止这种情况的发送。
2.transient 关键字:某些属性不应该被序列化到字节流中,可以使用 transient 关键字来标记这些属性。
假设我们有一个需要进行序列化的 Java 类,而因为密码很敏感,不希望在网络传输或存储时暴露出来。所以password 属性被标记为 transient 关键字,意味着该属性不会被序列化到字节流中。
解答:现在前后端数据传输和存储都使用JSON这种数据格式了,让公共返回对象实现Serializable接口,实现序列化成字节序列。这是使用@responseBody,又转成json返回形式进行网络传输,JSon序列后的字符串会自动转成字节流吗?是怎么样的流程?
步骤:先使用Jackson 的 ObjectMapper 将 Java 对象转换为 JSON 数据时,ObjectMapper 会将 JSON 数据序列化为字节序列。当从网络中接收到字节序列后,ObjectMapper 可以将其反序列化为 JSON 数据,再转换为对应的 Java 对象。
JSON序列化:将Java对象转换为JSON字符串的过程。
JSON反序列化是将JSON字符串转换为Java对象的过程。
JSON 是存储和交换文本信息的语法。类似 XML。Spring Boot 中,通常使用 Jackson 库来处理 JSON 数据的序列化和反序列化。在 TCP/IP 网络传输中;JSON 字符串会被转换为字节流进行传输。传输过程中,JSON 字符串会被转换为字节流进行传输:
首先,将 JSON 字符串按照某种编码方式(如 UTF-8)进行编码,将字符串中的每个字符转换为对应的字节序列;
然后,将编码后的字节序列按照客户端和服务器之间的约定进行传输;
最后,在接收端,根据约定的编码方式将接收到的字节序列解码为 JSON 字符串。



